
Learning the Lorenz System
Before digging into some of the saucy details of dynamical systems theory, I think it is time to introduce at least a bit of machine learning in this blog. The chance came naturally yesterday, as I wanted to learn how to use Jax, which is a sort of improved numpy, with a “functional soul”. I’m not digging into details about the codind part since I’m far for beeing confident with the library and this post will mainly revolve around the conceptual part of the topic. Yet, I will show all the code I used, so that you can follow through and appreciate the functionalities offered by Jax. If you are not confident with the machine learning ideas, you will maybe find some parts of this blogpost a bit mysterious, but you should still be able to follow through as I’ve tried to explain each step (at least at high-level, which is all we need for now).
Learning a dynamical system
In this post I will quickly expose what does it mean to learn a dynamical system and what are the differences with respect to the more classical problems one is used to when dealing with machine learning. Assume we are facing the following problem:
given a series of measurements ${x_0, x_1, \dots, x_t, \dots, x_T}$, we want to learn (i.e., estimate) the dynamical system generating them. This means assuming that our data were generated by an unknown process of the form:
\begin{equation}\label{eqn:discrete_system} x_{t+1} = G(x_t) \end{equation}
and we want to extimate $G$. Usually when dealing with this kind of tasks, one first creates a model of the system (e.g., assume that it is linear) and then uses the data to fit its parameter (e.g., find the entries of the matrix), but this would require some knowledge of the system under consideration. What if we do not know anything about the rule governing our system? Can we still hope to do something?
Yes, luckily.
We can actually do a lot using a model-agnostic data-driven approach.
Generating the data
As an example we will use the Lorenz system which we introduced last time, as it is one of the most studied one for this kind of problems, since it is quite simple but it displays all of the main features that one would like to have.
So first of all we need to generate the data. The Lorenz System is described by a differential equation that reads:
\[\begin{aligned} \frac{dx}{dt} &= \sigma (y - x) \\ \frac{dy}{dt} &= x (\rho - z) - y\\ \frac{dz}{dt} &= x y - \beta z. \\ \end{aligned}\]but since we are not interested in the particular details of our system (we are not even supposed to know them!) we will simply refer to it as:
\begin{equation}\label{eqn:continuos_system} \dot{x}(t) = g(x(t)) \end{equation}
where (with an abuse of notation) $x(t)$ will be our $3$-dimensional state, $\dot{x}(t)$ its time derivative and $g$ the function governing its evolution. Note that \eqref{eqn:discrete_system} is a continuous time system, described by a differential equation, and not a discrete system like the the one we are trying to learn. But, as described in a previous post, one has a discrete-time dynamical system naturally associated to a continuos time one, which is given by the integration of its equations of motion. So that \eqref{eqn:discrete_system} in our case will be:
\begin{equation} \label{eqn:final_system} x_{t+1} = G(x_t) = \int_{t \Delta }^{(t+1)\Delta} ds g(x(s)) \end{equation}
where $\Delta$ is our sampling time. Let’s move to the code.
First of all we need a function that simulates our system.
# define the lorenz equation
@jit
def lorenz(sigma, beta, rho, X, t):
x, y, z = X
xdot = sigma * (y - x)
ydot = x * (rho - z) - y
zdot = x * y - beta * z
return jnp.array([xdot, ydot, zdot])
# since the parameter are fixed, we use partial to create a new function that does not ask for them each time.
g = partial(lorenz, 10,8 / 3, 28 )
g = jit(g)
Using the just-in-time compiler provided by Jax, we can really accelerate the speed of our simulations.
The weird order of the argument (parameter first, then the state and lastly the time) of our lorenz function is justified by the use of partial: we now have our function g which does exactly what we want.
We define an initial condition $x_0$ (just $[1,1,1]$) and simulate a trajectory
# Initial condition
x_0 = jnp.ones(3)
# time intervals
t_vals= jnp.linspace(0., 450.,45000 )
#integrate the function to get the data
sol = odeint(g, x_0,t_vals)
#remove the transient, so that we only use points close to the attractor
X = sol[500:]
Let’s see what we get:
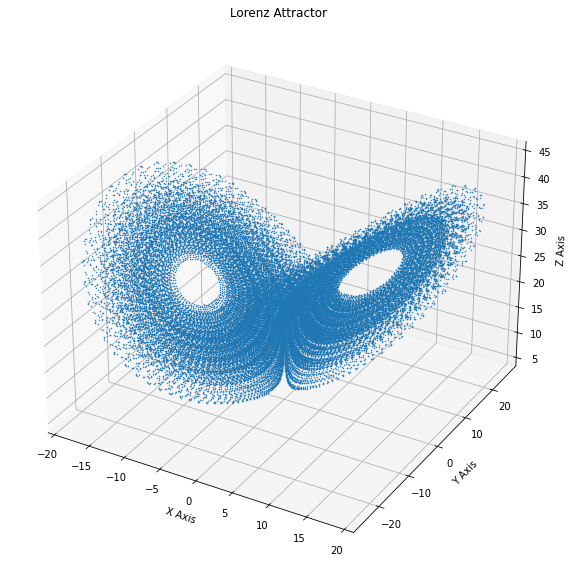
A machine learning perspective
Now we split the data into a training set and a test set. If you are not confident with this terms, don’t worry: for this purpose the training set is simply the data we have at our disposal to train the model, while the test set is just the future data that we aim at predicting and to which we will compare our prediction to assess its quality. We will discuss this issue later.
But what is the goal of our procedure?
We want to estimate a function which takes $x_t$ as an input and return $x_{t+1}$ as its output, for each $t$.
So, simply define a set X whose colums are the various $x_t$ and a Y whole colums are $x_{t+1}$.
We can think of this data as a series of couples (x_i, y_i) where $x_i$ is a feature vector and $y_i$ is a target vector.
The problem is now reduced to finding the best function $F$ for which
and this is what machine learning is great at doing!
L = 35000 #length of the training set
#define the training set
X_train = X[:L]
Y_train = X[1:L+1]
#defint the test set
X_test= X[L:-1]
Y_test = X[L+1:]
The model
Now that we know that we are looking for (a $F$) we need to create a procedure for finding a proper one. This is basic what ML is about: defining a class a functions and figuring out a way to find the best one, according to some metric.
For this purpose, we will use a neural network, which can be simply though of as a parametric class of functions:
\begin{equation} \label{eqn:predictor} y = F(x|\theta) \end{equation}
Our goal is to find the parameters configuration $\theta^* $ for which $ F(x|\theta^{*}) $ is as ‘‘close’’ as possible to $G$, using only the data. But what what do we mean by ‘‘close’’? This question is harder than one may think, expecially when dealing with dynamical systems.
But first, let us describe what our approach will be: we define a loss function \(L(\hat{y}_i,{y}_i)\) which accounts for the difference between the predicted output \(\hat{y}_{i} = F(x_{i}| \theta)\) and the expected output \({y}_i\) ( which is \(G(x_i)\)). We then search for the parameter configuration which minimizes this loss: this is the training of a neural network.
# Define the loss function (it will just be the Mean Squared Error)
def loss(params, inputs, targets):
# Computes average loss for the batch
predictions = net_apply(params, inputs)
return jnp.mean((targets - predictions)**2)
net_init, net_apply = stax.serial(
Dense(128), Relu,
Dense(128), Relu,
Dense(128), Relu,
Dense(3))
rng = random.PRNGKey(42)
in_shape = (-1,3)
out_shape, net_params = net_init(rng, in_shape)
(Please appreciate the functional style in which the network is defined when using Jax)
Now all we have is a model with random parameters. Let us see how it performs by applying it to all the data points.
#apply the predictor to all the points the the training sett
predictions = vmap(partial(net_apply, net_params))(X_train)
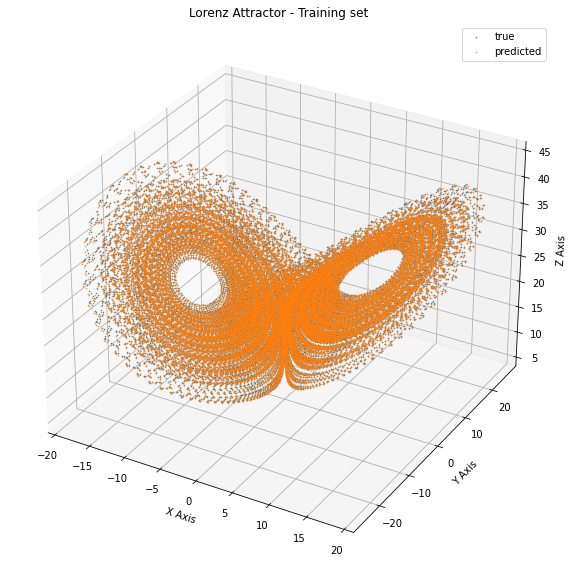
As expected, our prediction are definetly bad.
So now it is time for training.
First, define the optimizer and the optimization step:
#select adam as an optimizer
opt_init, opt_update, get_params = optimizers.adam(step_size = 1e-3)
#initialize its itial state
opt_state = opt_init(net_params)
# Define a compiled update step
@jit
def step(i, opt_state, x1, y1):
p = get_params(opt_state)
g = grad(loss)(p, x1, y1)
return opt_update(i, g, opt_state)
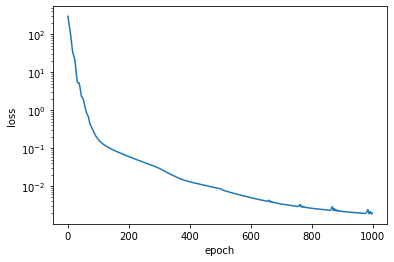
and then train the model by iterating again and again on the dataset, aiming at minimizing the loss
loss_list = []
for i in range(1000):
l = loss(get_params(opt_state), X_train, Y_train)
loss_list.append(l)
opt_state = step(i, opt_state, X_train, Y_train)
#if i%100==0: print (i, l)
net_params = get_params(opt_state)
print("final loss = ", loss_list[-1])
final loss = 0.0019449734
#apply the predictor to all the points the the training set
predictions = vmap(partial(net_apply, net_params))(X_train)
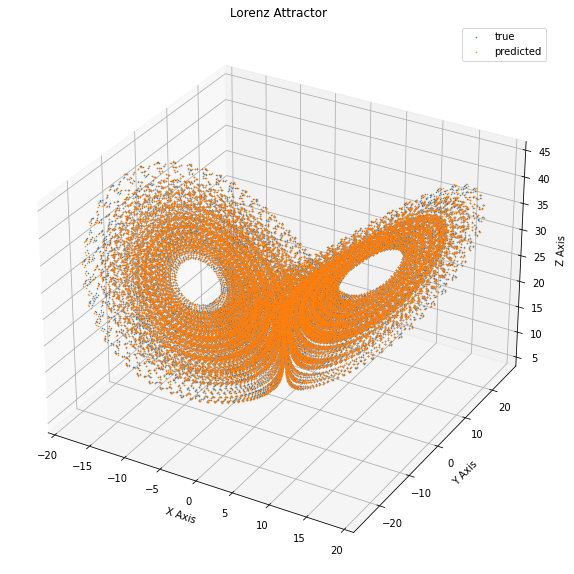
Let’s look at the trajectories:
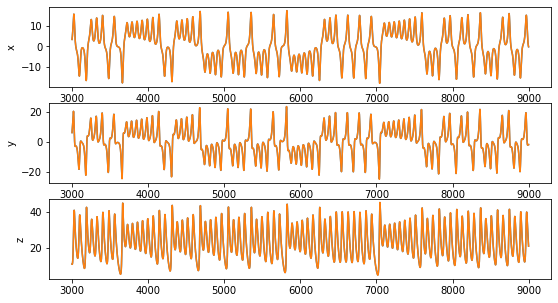
Now let’s see how the performance looks like on the test set:
#apply the predictor to all the points the the training sett
test_predictions = vmap(partial(net_apply, net_params))(X_test)
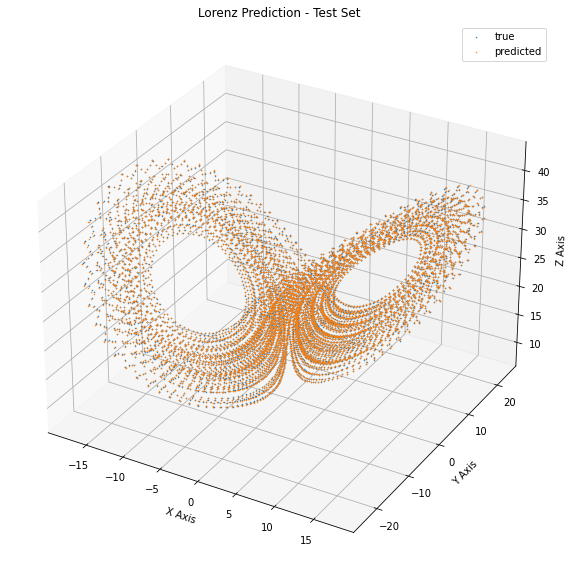
This seems pretty nice. Our performance on the test set seems accurate at each point. Can we be happy? No, not at all.
Learning a dynamical systems means learning its dynamics
Let’s go back and think about what we did. We created a model which is able to predict a $y$ when given and $x$ and we interpreted this as a step in time. But the property of a dynamical systems are inherently given by the fact that it is dynamical. The temporal stucture of the data is reflected by the fact that each sample is given by the application of $G$ on the previous one, as Eq.\ref{eqn:discrete_system} states. So in order to actually validate our system, we should use $F(x|\theta^*)$ to generate a trajecory, by iteratively applying it to its own prediction, i.e.,
\begin{equation} x_{t+1} = F(x_t| \theta^*) \end{equation}.
Let’s code it:
def produce_trajectory(model, x_0, n_steps):
X_hat = [x_0]
for t in range(n_steps):
y = model(x_0)
X_hat.append(y)
x_0 = y
return jnp.array(X_hat)
final_model = partial(net_apply, net_params)
final_model= jit(final_model)
L_test = X_test.shape[0]
X_hat = produce_trajectory(final_model, X_test[0], L_test)
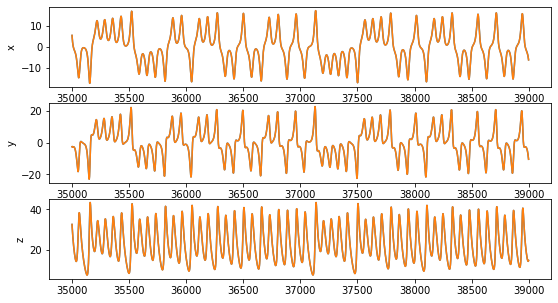
The results are not so inspiring:
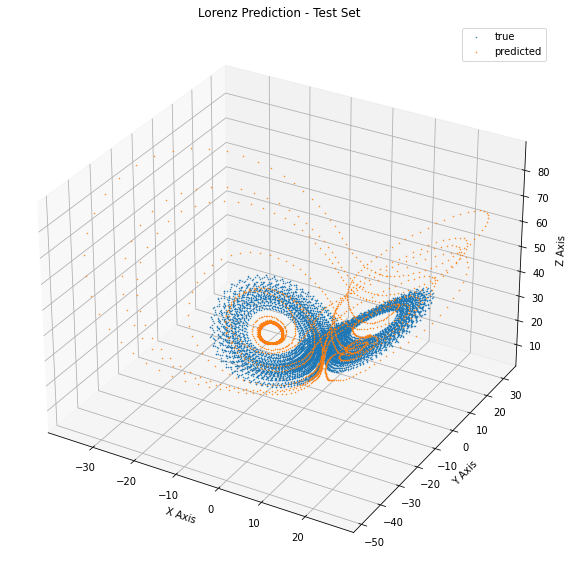
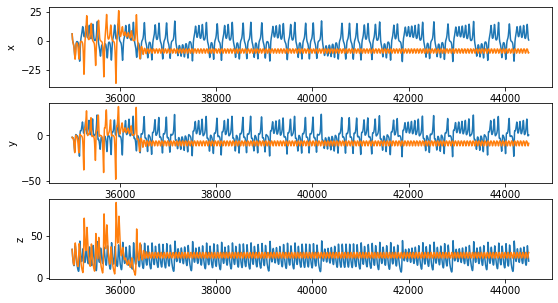
We see that the generated trajectory only vaguely resembles the one of the Lorenz system: after an initial wonder in the state space, it reaches a steady oscillatory behavior. This means that the systems we have learned it is actually different from the Lorenz system.
Conclusions
This example wanted to show that the learning process which one use in machine learning displays some additional conceptual difficulties when applied to the prediction of dynamical systems. In particular, the validation procedure must be re-thought, as predicting each point (more or less) correctly does not lead to a correct approximation of the trajectories when the predictor is used to generate one. In fact, when I started writing this post I didn’t expect the simulated trajectory to be so bad. And notice that the problem in this case is made even harder by the fact that we are dealing with a chaotic system, where any error will be amplified exponentially. But we will talk more in detail about these issues in the future.
Of course there are some techniques which allows one to perform much better than this, otherwise I would not have much to write in this blog. But in order to appreciate them, we need to explore more in detail the properties of dynamical systems and also to dig a bit more into machine learning theory. And we will.